Large language models (LLMs)
PandasAI supports several large language models (LLMs). LLMs are used to generate code from natural language queries. The generated code is then executed to produce the result.
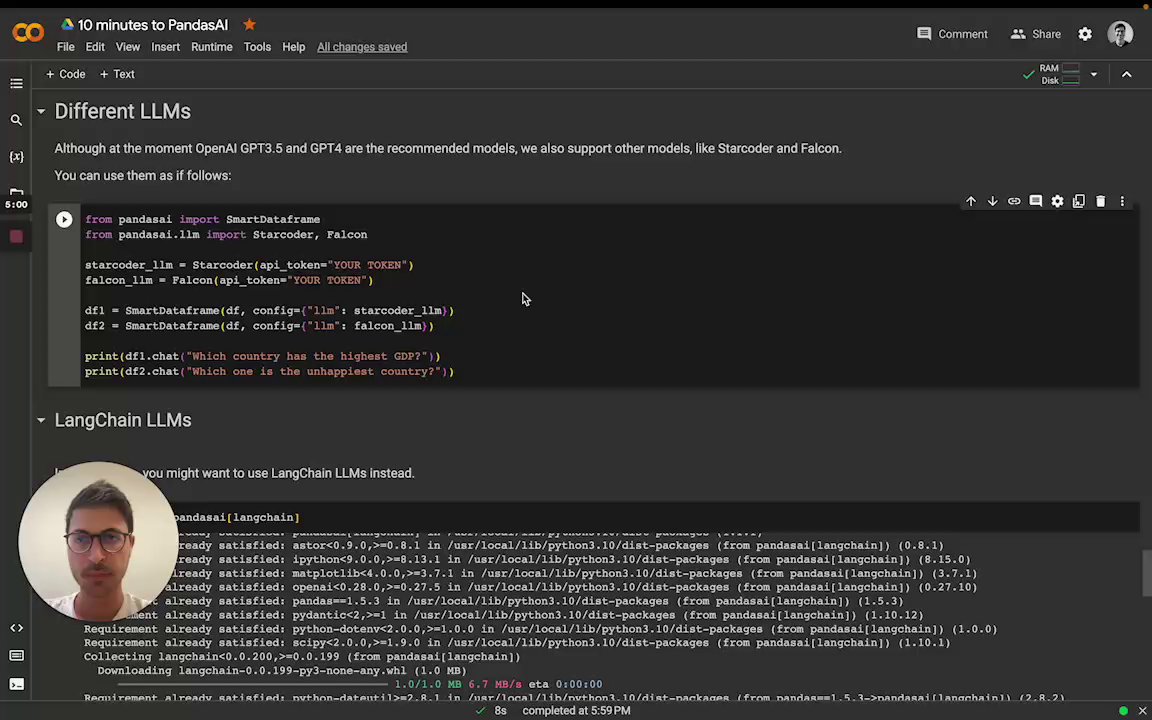
You can either choose a LLM by instantiating one and passing it to the SmartDataFrame or SmartDatalake constructor,
or you can specify one in the pandasai.json file.
If the model expects one or more parameters, you can pass them to the constructor or specify them in the pandasai.json
file, in the llm_options param, as it follows:
{
"llm": "BambooLLM",
"llm_options": {
"api_key": "API_KEY_GOES_HERE"
}
}
BambooLLM
BambooLLM is the state-of-the-art language model developed by PandasAI with data analysis in mind. It is designed to understand and execute natural language queries related to data analysis, data manipulation, and data visualization. It's currently in closed beta and available only to a select group of users, but it will be available to the public soon. You can join the waitlist here.
from pandasai import SmartDataframe
from pandasai.llm import BambooLLM
llm = BambooLLM(api_key="my-bamboo-api-key")
df = SmartDataframe("data.csv", config={"llm": llm})
response = df.chat("Calculate the sum of the gdp of north american countries")
print(response)
As an alternative, you can set the PANDASAI_API_KEY environment variable and instantiate the BambooLLM object
without passing the API key:
from pandasai import SmartDataframe
from pandasai.llm import BambooLLM
llm = BambooLLM() # no need to pass the API key, it will be read from the environment variable
df = SmartDataframe("data.csv", config={"llm": llm})
response = df.chat("Calculate the sum of the gdp of north american countries")
print(response)
OpenAI models
In order to use OpenAI models, you need to have an OpenAI API key. You can get one here.
Once you have an API key, you can use it to instantiate an OpenAI object:
from pandasai import SmartDataframe
from pandasai.llm import OpenAI
llm = OpenAI(api_token="my-openai-api-key")
pandas_ai = SmartDataframe("data.csv", config={"llm": llm})
As an alternative, you can set the OPENAI_API_KEY environment variable and instantiate the OpenAI object without
passing the API key:
from pandasai import SmartDataframe
from pandasai.llm import OpenAI
llm = OpenAI() # no need to pass the API key, it will be read from the environment variable
pandas_ai = SmartDataframe("data.csv", config={"llm": llm})
If you are behind an explicit proxy, you can specify openai_proxy when instantiating the OpenAI object or set
the OPENAI_PROXY environment variable to pass through.
Count tokens
You can count the number of tokens used by a prompt as follows:
"""Example of using PandasAI with a pandas dataframe"""
from pandasai import SmartDataframe
from pandasai.llm import OpenAI
from pandasai.helpers.openai_info import get_openai_callback
import pandas as pd
llm = OpenAI()
# conversational=False is supposed to display lower usage and cost
df = SmartDataframe("data.csv", config={"llm": llm, "conversational": False})
with get_openai_callback() as cb:
response = df.chat("Calculate the sum of the gdp of north american countries")
print(response)
print(cb)
# The sum of the GDP of North American countries is 19,294,482,071,552.
# Tokens Used: 375
# Prompt Tokens: 210
# Completion Tokens: 165
# Total Cost (USD): $ 0.000750
Google PaLM
In order to use Google PaLM models, you need to have a Google Cloud API key. You can get one here.
Once you have an API key, you can use it to instantiate a Google PaLM object:
from pandasai import SmartDataframe
from pandasai.llm import GooglePalm
llm = GooglePalm(api_key="my-google-cloud-api-key")
df = SmartDataframe("data.csv", config={"llm": llm})
Google Vertexai
In order to use Google PaLM models through Vertexai api, you need to have
- Google Cloud Project
- Region of Project Set up
- Install optional dependency
google-cloud-aiplatform - Authentication of
gcloud
Once you have basic setup, you can use it to instantiate a Google PaLM through vertex ai:
from pandasai import SmartDataframe
from pandasai.llm import GoogleVertexAI
llm = GoogleVertexAI(project_id="generative-ai-training",
location="us-central1",
model="text-bison@001")
df = SmartDataframe("data.csv", config={"llm": llm})
Azure OpenAI
In order to use Azure OpenAI models, you need to have an Azure OpenAI API key as well as an Azure OpenAI endpoint. You can get one here.
To instantiate an Azure OpenAI object you also need to specify the name of your deployed model on Azure and the API version:
from pandasai import SmartDataframe
from pandasai.llm import AzureOpenAI
llm = AzureOpenAI(
api_token="my-azure-openai-api-key",
azure_endpoint="my-azure-openai-api-endpoint",
api_version="2023-05-15",
deployment_name="my-deployment-name"
)
df = SmartDataframe("data.csv", config={"llm": llm})
As an alternative, you can set the AZURE_OPENAI_API_KEY, OPENAI_API_VERSION, and AZURE_OPENAI_ENDPOINT environment
variables and instantiate the Azure OpenAI object without passing them:
from pandasai import SmartDataframe
from pandasai.llm import AzureOpenAI
llm = AzureOpenAI(
deployment_name="my-deployment-name"
) # no need to pass the API key, endpoint and API version. They are read from the environment variable
df = SmartDataframe("data.csv", config={"llm": llm})
If you are behind an explicit proxy, you can specify openai_proxy when instantiating the AzureOpenAI object or set
the OPENAI_PROXY environment variable to pass through.
HuggingFace via Text Generation
In order to use HuggingFace models via text-generation, you need to first serve a supported large language model (LLM). Read text-generation docs for more on how to setup an inference server.
This can be used, for example, to use models like LLaMa2, CodeLLaMa, etc. You can find more information about text-generation here.
The inference_server_url is the only required parameter to instantiate an HuggingFaceTextGen model:
from pandasai.llm import HuggingFaceTextGen
from pandasai import SmartDataframe
llm = HuggingFaceTextGen(
inference_server_url="http://127.0.0.1:8080"
)
df = SmartDataframe("data.csv", config={"llm": llm})
LangChain models
PandasAI has also built-in support for LangChain models.
In order to use LangChain models, you need to install the langchain package:
pip install pandasai[langchain]
Once you have installed the langchain package, you can use it to instantiate a LangChain object:
from pandasai import SmartDataframe
from langchain_openai import OpenAI
langchain_llm = OpenAI(openai_api_key="my-openai-api-key")
df = SmartDataframe("data.csv", config={"llm": langchain_llm})
PandasAI will automatically detect that you are using a LangChain LLM and will convert it to a PandasAI LLM.
Amazon Bedrock models
In order to use Amazon Bedrock models, you need to have an AWS AKSK and gain the model access.
Currently, only Claude 3 Sonnet is supported.
In order to use Bedrock models, you need to install the bedrock package.
pip install pandasai[bedrock]
Then you can use the Bedrock models as follows
from pandasai import SmartDataframe
from pandasai.llm import BedrockClaude
import boto3
bedrock_runtime_client = boto3.client(
'bedrock-runtime',
aws_access_key_id=ACCESS_KEY,
aws_secret_access_key=SECRET_KEY
)
llm = BedrockClaude(bedrock_runtime_client)
df = SmartDataframe("data.csv", config={"llm": llm})
More ways to create the bedrock_runtime_client can be found here.
More information
For more information about LangChain models, please refer to the LangChain documentation.
IBM watsonx.ai models
In order to use IBM watsonx.ai models, you need to have
- IBM Cloud api key
- Watson Studio project in IBM Cloud
- The service URL associated with the project's region
The api key can be created in IBM Cloud.
The project ID can determined after a Watson Studio service
is provisioned in IBM Cloud. The ID can
then be found in the
project’s Manage tab (Project -> Manage -> General -> Details). The service url depends on the region of the
provisioned service instance and can be
found here.
In order to use watsonx.ai models, you need to install the ibm-watsonx-ai package.
At this time, watsonx.ai does __not__ support the PandasAI agent.
pip install pandasai[ibm-watsonx-ai]
Then you can use the watsonx.ai models as follows
from pandasai import SmartDataframe
from pandasai.llm import IBMwatsonx
llm = IBMwatsonx(
model="ibm/granite-13b-chat-v2",
api_key=API_KEY,
watsonx_url=WATSONX_URL,
watsonx_project_id=PROJECT_ID,
)
df = SmartDataframe("data.csv", config={"llm": llm})
More information
For more information on the watsonx.ai SDK you can read more here.
Local models
PandasAI supports local models, though smaller models typically don't perform as well. To use local models, first host one on a local inference server that adheres to the OpenAI API. This has been tested to work with Ollama and LM Studio.
Ollama
Ollama's compatibility is experimental (see docs).
With an Ollama server, you can instantiate an LLM object by specifying the model name:
from pandasai import SmartDataframe
from pandasai.llm.local_llm import LocalLLM
ollama_llm = LocalLLM(api_base="http://localhost:11434/v1", model="codellama")
df = SmartDataframe("data.csv", config={"llm": ollama_llm})
LM Studio
An LM Studio server only hosts one model, so you can instantiate an LLM object without specifying the model name:
from pandasai import SmartDataframe
from pandasai.llm.local_llm import LocalLLM
lm_studio_llm = LocalLLM(api_base="http://localhost:1234/v1")
df = SmartDataframe("data.csv", config={"llm": lm_studio_llm})